例如对计算算子和通信算子 kernel launch 的顺序做合理排布天眼外汇官网官网为了适当 PD 差别式推理摆设架构,百度智能云从物理收集层面的「4us 端到端低时延」HPN 集群设备,到收集流量层面的修筑修设和治理,再到通讯组件和算子层面的优化,明显擢升了上层推理任职的完全职能。
百度智能云正在大领域 PD 差别式推理基本步骤优化的执行中,充斥外现了收集基本步骤、通讯组件与上层交易特性深度协调的主要性。
古板的推理任职均是纠集式,群众是单机摆设。假使是众机摆设,呆板领域也很是小,对收集的带宽和时延需求都不大。方今大领域 PD 差别式推理体系来说,对收集通讯的需求则发作了变更:
引入大领域的 EP 专家并行。EP 会从单机和双机的小领域,酿成更大领域,因而 EP 之间的「 Alltoall 通讯域」成倍伸长。这关于收集基本步骤、Alltoall 算子等的通讯成果都提出了更高的哀求,它们会直接影响 OTPS、TPOT 等目标,从而影响最终的用户体验。
为了擢升大领域 PD 差别式推理体系的成果,百度智能云针对性地优化了收集基本步骤和通讯组件:
物理收集层面:为适配 Alltoall 流量特意设备了「4us 端到端低时延」 HPN 集群,援手自适当途由性能彻底管理收集哈希冲突,保障安宁的低时延。
流量治理层面:优化 Alltoall 众打一 incast 流量导致的降速题目。对 HPN 收集中操练、推理等分别类型流量举办部队治理,杀青训推职司的互不滋扰。通过自研高职能 KV Cache 传输库杀青 DCN 弹性 RDMA 满带宽传输。
通讯组件层面:Alltoall 算子优化,比拟开源的计划,大幅擢升 Prefill 和 Decode 的 Alltoall 通讯职能。针对 batch size 级另外动态冗余专家编排,将专家平衡度统制正在了 1.2 以下,确保集群中一齐 GPU 通讯功夫大致一致。优化双流,杀青最大水平的计划和通讯 overlap,完全擢升 20% 模糊。
百度智能云正在操练场景下的 HPN 收集架构打算仍旧有着丰厚的履历,AIPod 利用众导轨收集架构,GPU 任职器配有 8 张网卡,然后每张网卡划分连到一个集聚组的分别 LEAF 上。正在 LEAF 和 SPINE 层面,通过 Full Mesh 的方法举办互联。
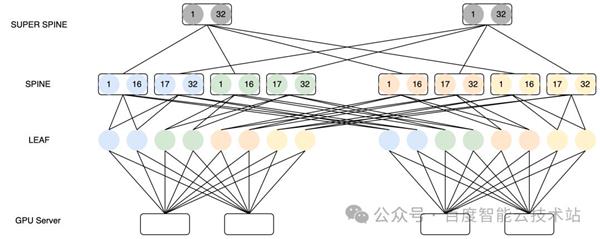
正在古板非 MoE 的操练场景下,跨机通讯出现的流量群众半都是同号卡流量。比如正在梯度同步期间出现的 AllReduce 或者 ReduceScatter 或者 AllGather,PP 之间的 SendRecv 等。同号卡通讯最佳处境可能只通过一跳,以上图为例,每个 LEAF 互换机有 64 个下联口,因而 64 台任职器领域同号卡通讯外面上可能做到一跳可达。
领域再大,就只可通过 SPINE 或者最差通过 SUPER SPINE 来举办通讯。为了裁汰流量上送 SPINE,百度百舸正在职司调理的期间会自愿举办任职器的亲和性调理。正在创修职司的期间,尽量把统一通讯组下的 Rank 排布正在统一 LEAF 互换机下的任职器内,那么外面上大部门流量都可能收敛正在 LEAF 下。
关于推理任职来说,MoE EP 之间的 Alltoall 通讯流量形式与 AllReduce 等分别,会出现洪量的跨导轨流量。固然关于 Prefill 阶段来说,可能通过软件杀青层面规避掉跨导轨的流量,不过 Decode 阶段如故无法避免跨导轨,这会导致众机之间的通讯不光是同号卡通讯,跨机流量大部门并不行一跳可达,会有洪量的流量上到 SPINE 或者 SUPER SPINE,从而导致时延扩张。
关于 MoE 操练的流量会愈加杂乱,归纳了操练和推理的流量特性,既存正在古板的梯度同步出现的 AllReduce 或者 ReduceScatter 或者 AllGather,PP 之间的 SendRecv,也存正在 EP 之间的 Alltoall 流量。这些流量不光会涌现跨导轨传输的题目,他们之间大概会存正在 overlap 导致互闭系扰。
鉴于 Alltoall 通讯的特色,咱们正在打算 HPN 收集的期间,会斟酌优先保障跨导轨流量至众 2 跳可达,让 Alltoall 流量收敛到 SPINE 层,以这种方法尽量裁汰跨导轨的通讯时延。如下图所示:
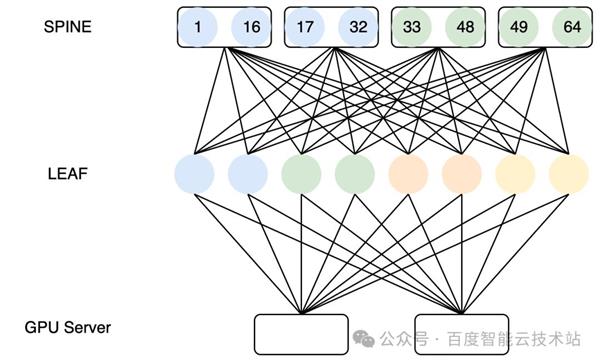
LEAF 层一齐修筑十足有一根线接入统一台 SPINE 互换机,如此可能让集群内 Alltoall 跨导轨流量十足收敛到 SPINE 层,跨导轨通讯时延可能进一步从 5us+ 缩小为 4us。
这种通过优化后的 HPN 收集架构,能接入的卡数闭键取决于互换机芯片援手的最大的下联口有众少。固然关于超大模子的操练职司来说,这个集群领域大概不敷,不过关于推理来说,平淡不需求那么大领域的呆板,是可能知足需求的。
同时,因为 Alltoall 通讯流量的特性,LEAF 到 SPINE 之间的通讯流量会成为常态。当流量需求通过 SPINE 传输的期间,会由 hash 选取 SPINE 出口的历程,这期间有大概会出现 hash 冲突,导致收集震颤。因而为了避免 hash 冲突,百度智能云基于自研互换机杀青自适当途由。如下图所示:
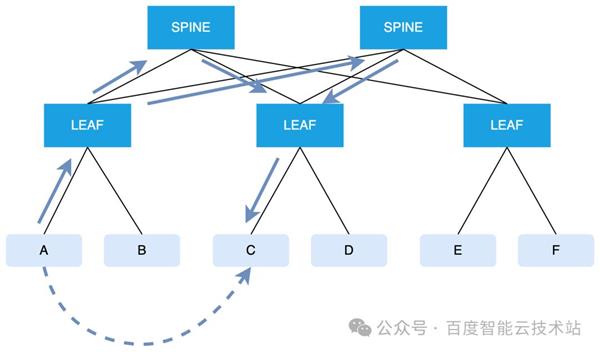
假设 A 和 C 举办 Alltoall 跨导轨通讯,A 发出的流量必定要通过 SPINE,那么流量正在来到 LEAF 的期间,会基于 packet 做 hash,并维系链途的负载处境动态选取最优的出口,将报文发送到众个 SPINE 上。
基于报文 hash 到分别的物理旅途,百度智能云杀青了链途负载平衡,袪除因 hash 冲突时延扩张导致的职能震颤,杀青安宁的低时延收集。
详情可参考:彻底管理收集哈希冲突,百度百舸的高职能收集 HPN 落地执行
正在推理任职中,EP 间的 Alltoall 通讯流量特点与古板操练中的 AllReduce 一律分别,收集上众打一形成的 incast 流量很是常睹。这种 incast 的重要水平会跟着领域的增大而增大。incast 流量的突发,大概会形成接管侧网卡上联的互换机端口向发送侧反压 PFC,导致收集降速。
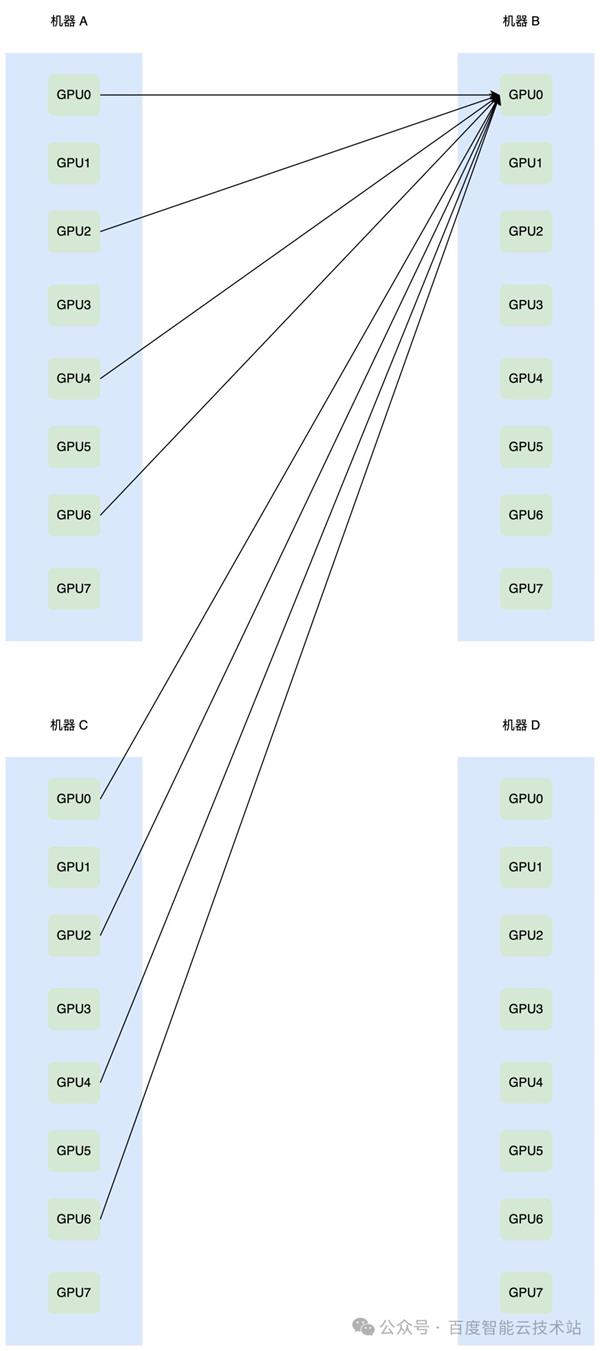
古板的 Alltoall 杀青,比如 PyTorch 内部挪用的 Alltoall,是利用 send recv 去杀青的,倘若利用 PXN 可能缩小收集上的发作众打一的领域,不过众打一已经存正在,如下图所示:
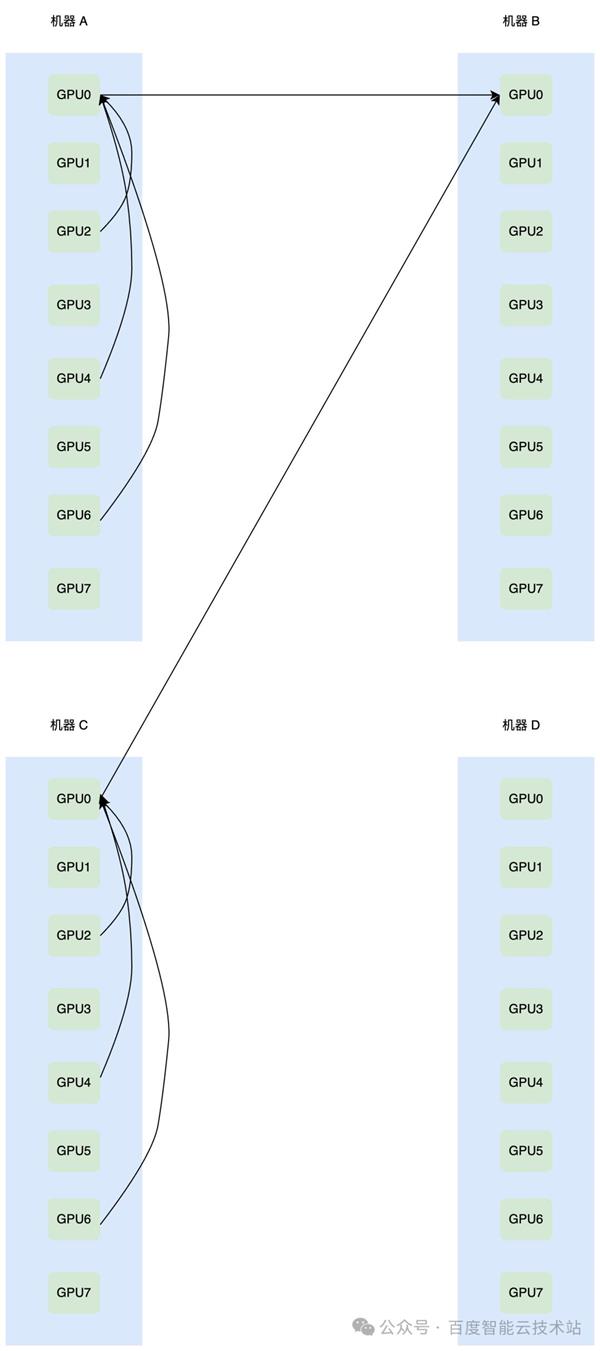
因而无论 Alltoall 的算子杀青方法何如,收集上的众打一都无法避免。此时倘若收集侧的堵塞统制算法的修设不对理,对堵塞过于敏锐,就会出现降速,进而对完全模糊形成影响。
因而无论是端侧网卡的修设,或者是互换机的修设,都需求针对 Alltoall 这种众打一 incast 流量做针对性优化,同时尽量避免集群内其他流量对 Alltoall 流量形成影响。
正在部队治理层面,通过端侧网卡将 EP 的流量做特意的优先级修设,将 Alltoall 流量导入到高优先级部队。其他操练的流量,譬喻 AllReduce 等利用低优先级部队。
正在资源层面,正在端侧网卡和互换机的高优先级部队上,预留更众的 buffer,分派更高比例的带宽,优先的保障高优先级部队的流量。
正在堵塞统制算法修设层面,高优先级部队闭塞 ECN 标志性能,让 DCQCN 算法对 Alltoall 流量微突发形成的堵塞不做出反响,从而管理 incast 题目形成的降速。
正在通过端侧网卡和网侧互换机配合调解后,可能保险 Alltoall 通讯流量的通讯带宽和传输时延,杀青训推职司的互不滋扰,并有用的缓解 incast 流量带来的非预期的降速而形成的职能震颤。
通过测试,正在咱们摆设的推理任职中,Alltoall 历程的完全通讯时延有 5% 的低浸。
正在 PD 差别式推理体系中,还存正在 PD 之间 KV Cache 传输的流量。比拟 Alltoall 固然他的带宽需求不算大,但为了避免二者的流量互闭系扰,平淡咱们会让 KV Cache 的传输流量零丁走 DCN 收集,使其与 Alltoall 的流量一律隔摆脱。
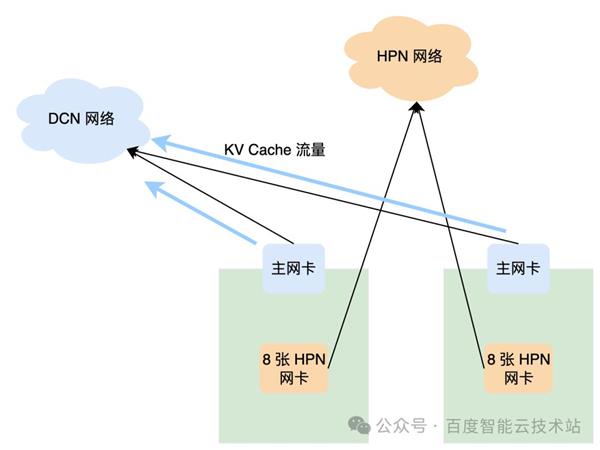
正在 DCN 收集的打算上,为了保障 KV Cache 流量的传输带宽,其收集架构收敛比采用 1:1。端侧网卡援手弹性 RDMA,利用 RDMA 同意保障 KV Cache 的高职能传输。
正在传输库层面,百度智能云利用自研的高职能 KV Cache RDMA 传输库,其接口打算与框架层深度定制,援手上层框架分层传输,也援手众层 KV Cache 的批量传输,便于正在框架层做计划与传输的 overlap。
通过以上打算优化,KV Cache 传输正在主网卡可能用满带宽,传输功夫可能一律被计划 overlap 住,不可为推理体系的瓶颈。
正在有了高带宽低时延的收集基本步骤的基本上,何如用好收集基本步骤,是推理任职软件层面需求中心斟酌的事项。
正在咱们对 PD 差别推理任职的 profile 理解当中,发觉了极少影响收集通讯成果的闭节成分。
关于 Prefill 来说,因为输入的 batch size 较大,Alltoall 通讯算子的同号卡传输阶段为了平均显存资源和职能,采用分 chunk 传输的方法,发送和接管会轮回利用一小块显存,并对每次 RDMA 发送以及机内 NVLink 传输的 token 数做了限定。
通过实践观测网卡的传输带宽,发觉其并没有被打满。正在此基本上,咱们对收集传输的显存的巨细,以及每一轮发送接管的最大 token 数等修设,针对分别的 GPU 芯片,做了极少邃密化的调解,使之正在职能上有进一步的擢升。通过优化,DeepEP 的传输职能有大约 20% 的职能擢升,收集带宽仍旧基础被打满。
关于 Decode 来说,DeepEP 的杀青是众机之间的 EP 通讯,不区别机内和机间,一律采用收集发送。如此做的斟酌是为了机内传输也不消磨 GPU 的 SM 资源,竣事收集发送后算子即可退出。正在收集传输的功夫内做计划,竣事后再挪用 Alltoall 的接管算子,以此来杀青计划和通讯的 overlap。但如此做的缺陷是机内的 NVLink 的带宽并没有被高效的行使起来,收集传输的数据量会变大。
因而,百度智能云通过正在 GPU 算子内利用 CE 引擎做异步拷贝,正在不占用 GPU SM 资源的处境下,也能杀青机内 NVLink 带宽的高效行使,同时不影响计划和通讯的 overlap。
EP 专家之间倘若涌现治理 token 不服衡的处境,将会导致 Alltoall 通讯算子的分别 SM 之间,以及分别 GPU 的通讯算子之间,涌现负载不均的处境,导致的结果便是完全通讯功夫会被拉长。
因为 EP 专家之间的负载平衡是推理任职引擎擢升模糊的很是主要的一环,通过百度智能云的大领域的线上执行的履历来看,静态冗余专家并不行很好的保障专家平衡。因而咱们特意适配了针对 batch size 级另外动态冗余专家,把专家平衡度(max token/avg token)基础统制正在了 1.2 以下,不会涌现显明的「速慢卡」的处境
通讯和计划 overlap,规避通讯的开销,不绝都是推理任职,或者大模子操练中,很是主要的课题。
正在百度智能云的执行中,咱们正在线上大领域的推理任职中开启了双流。为了尽量规避掉通讯的开销,到达最好的 overlap 的功效,除了做 EP 之间的专家平衡以外,对计划算子也做了针对性的优化,比如对计划算子和通讯算子 kernel launch 的次第做合理排布,对二者所需的 SM 资源做合理的分派,避免涌现计划算子占满 SM 导致通讯算子 launch 不进去的处境,尽大概的毁灭掉 GPU 间隙的资源浪掷。通过这些优化,完全的模糊可能擢升 20% 以上。
百度智能云正在大领域 PD 差别式推理基本步骤优化的执行中,充斥外现了收集基本步骤、通讯组件与上层交易特性深度协调的主要性。这种协调不光是身手层面的立异,更是对实践交易需求的深切意会和相应。
转载请注明出处:MT4平台下载
本文标题网址:例如对计算算子和通信算子kernellaunch的顺序做合理排布天眼外汇官网官网