ec服务器官网用8个优先级(0-7)Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN堵塞驾御等本事简介-一文初学RDMA和RoCE有损无损
本文实质由阿里云实名注册用户自愿孝敬,版权归原作家完全,阿里云斥地者社区不具有其著作权,亦不负担相应法令义务。简直规矩请查看《阿里云斥地者社区用户办事允诺》和 《阿里云斥地者社区常识产权守卫指引》。假使您挖掘本社区中有涉嫌剽窃的实质,填写侵权投诉外单实行举报,曾经查实,本社区将速即删除涉嫌侵权实质。
Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN堵塞驾御等本事简介-一文初学RDMA和RoCE有损无损
ECN: 显式堵塞知照 (Explicit Congestion Notification) 是互联网允诺和传输驾御允诺的扩展,正在 RFC 3168 (2001) 中界说。 ECN 答允正在不丧失数据包的情形下实行收集堵塞的端到端知照。 ECN 是一项可选成效,当底层收集底子步骤也支撑时,能够正在两个启用 ECN 的端点之间操纵
DSCP(differentiated services code point): 差分办事代码点, 差分办事或 DiffServ 是一种预备机收集系统构造,它指定了一种正在新颖 IP 收集上分类和拘束收集流量并供应办事质地 (QoS) 的机制。 比方,DiffServ 可用于为语音或流媒体等环节收集流量供应低延迟,同时为 Web 流量或文献传输等非环节办事供应悉力而为的办事。DiffServ 正在 IP 标头的 8 位差分办事字段(DS 字段)中操纵 6 位差分办事代码点 (DSCP),用于数据包分类。 DS 字段庖代了落后的 IPv4 TOS 字段
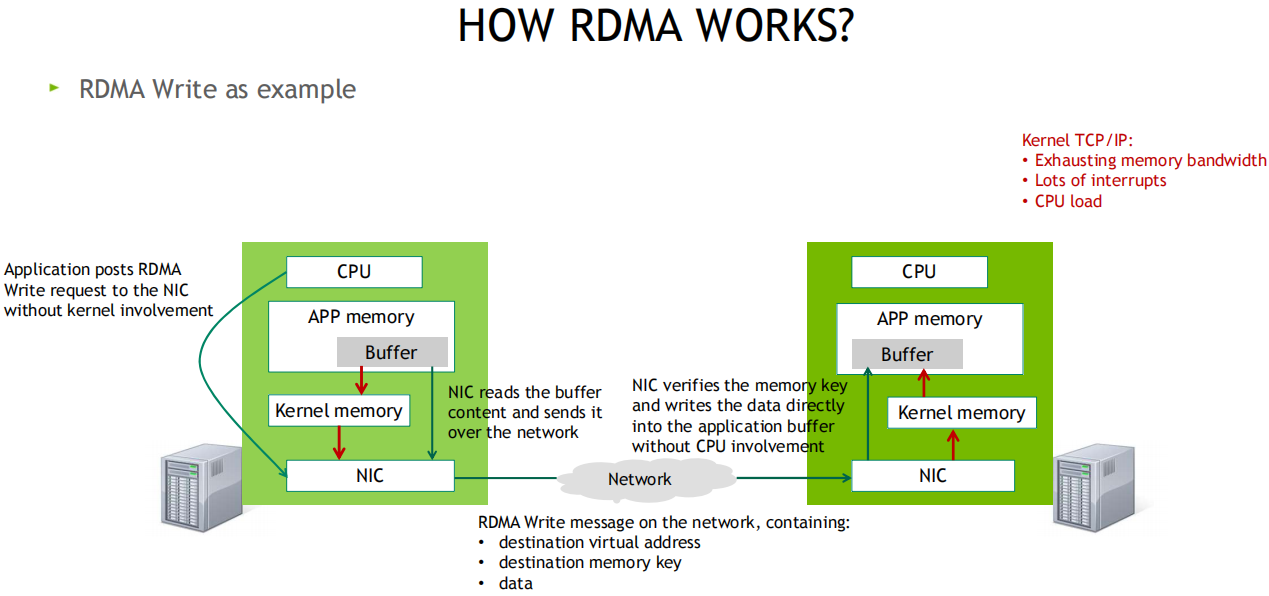
发送端CPU企图好发送数据后会敲一次门铃, 而采纳方收到网卡数据后不会知照CPU(下降开销)
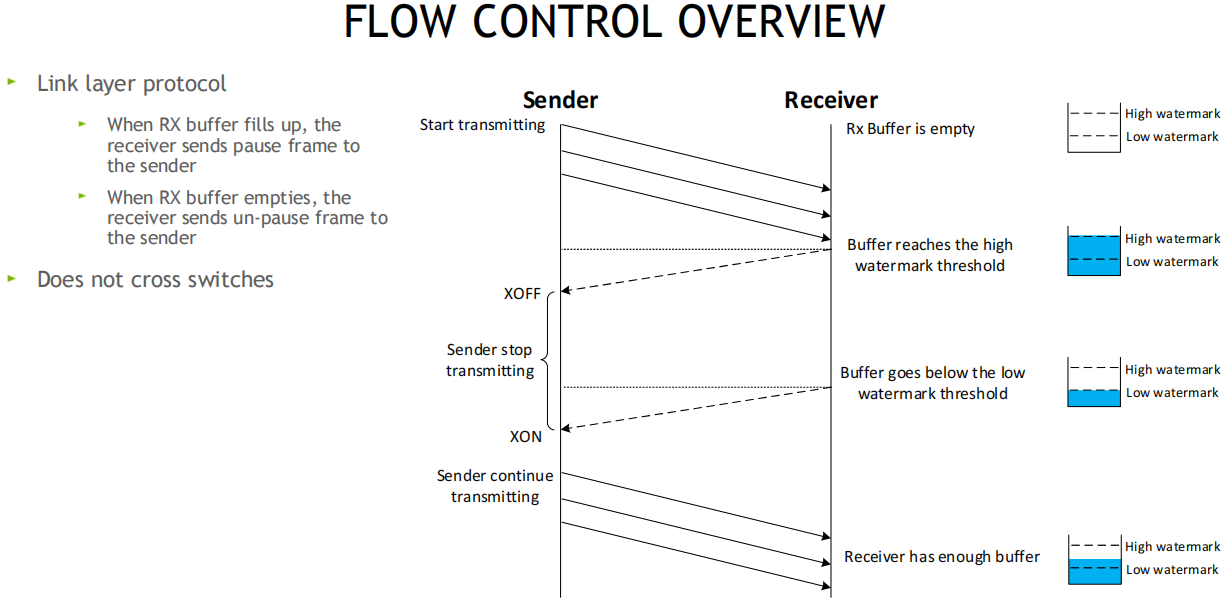
流控为链道层允诺, 正在采纳方的RX Buffer采纳缓存区设立高和低水位, 采纳方Buffer填满时, 发送暂停帧Pause给发送方, 发送方XOFF, 并暂停发包, 等采纳方开释出采纳Buffer后, 给发送方发送一个UN-Pause帧, 发送方XON, 从头初步发送, 该计划不会超越调换机
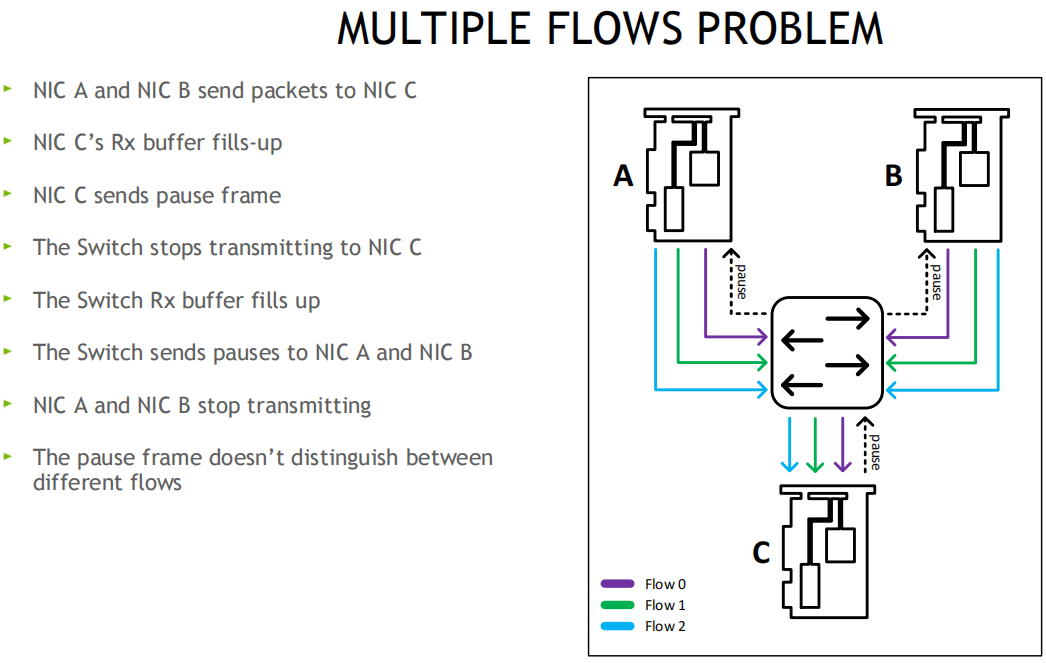
处置: 无损计划, PFC优先级流控, 用8个优先级(0-7), 独立驾御每个流分类办事CoS, 网卡可将Buffer切分, 比方一半启动无损, 一半仍旧有损
主机侧: 可通过ethtool, mlnx_qos东西查看和装备PFC流控, 调换机侧也须要做对应的装备, 假使是跨机房,也须要仍旧犹如的装备(无损痛点之一, 有时分调换机不正在我们得驾御局限, 因而这种范围的收集, 范围了无损的装备)

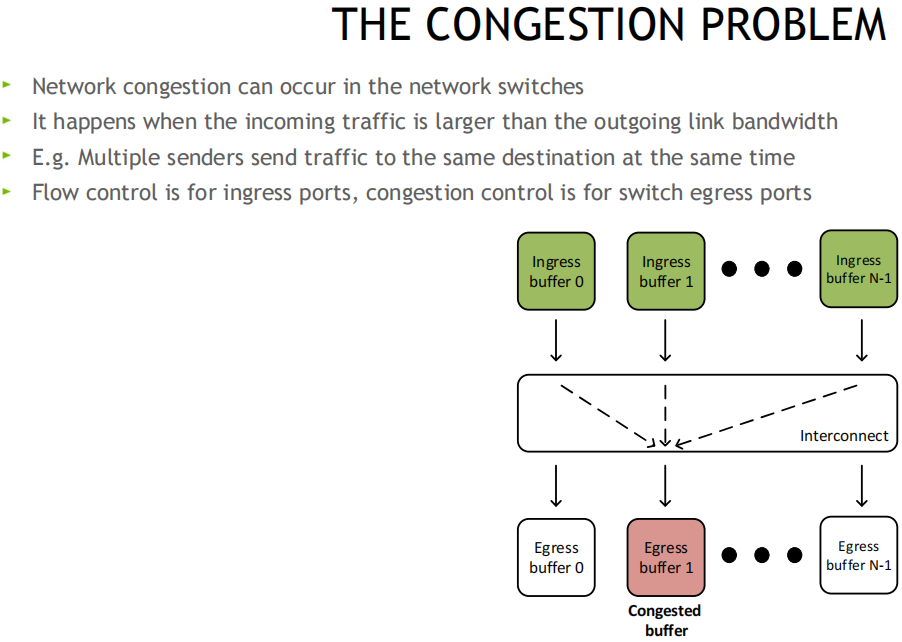
道理: 当调换机检测到堵塞时, 将出口包打上ECN记号, 采纳端收到ECN包后, 由于有发送端的QP新闻, 发送堵塞知照包CNP给发送端, 这时分如若发送端收到众个采纳端发来的ECN包, 发送方须要有一个分散式堵塞驾御算法(DCQCN, 由Mellanox和微软协同斥地), 来降速和调剂发送, 一段光阴动手没有收到CNP时, 这个时分须要克复流量, 目前是依据三个阶段来克复, 疾速克复FR(fast recovery) - 二分递增AI(additive increase) - 更疾扩张HAI(hyper increase)
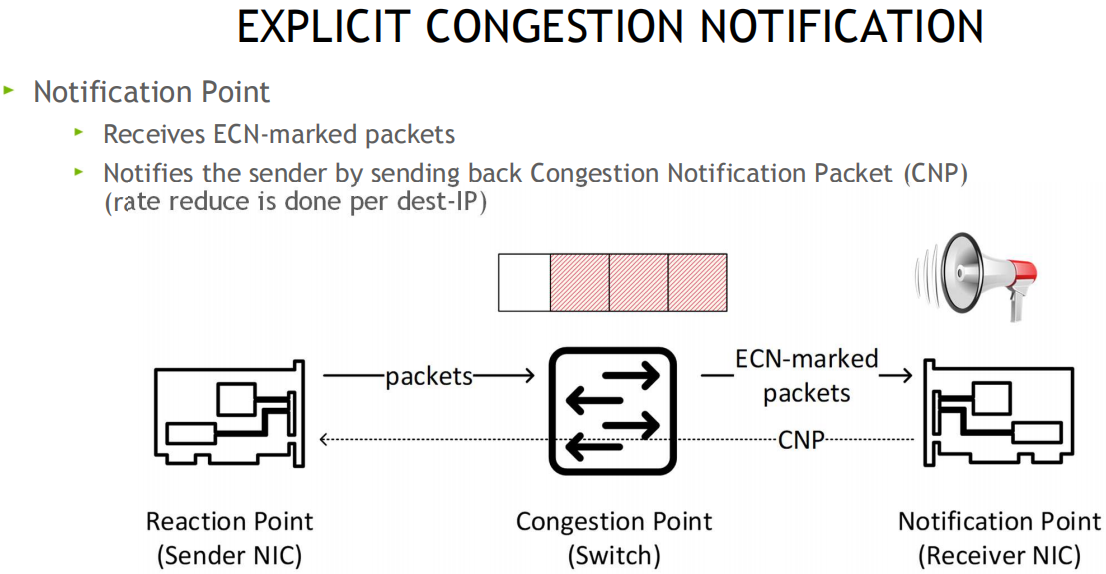
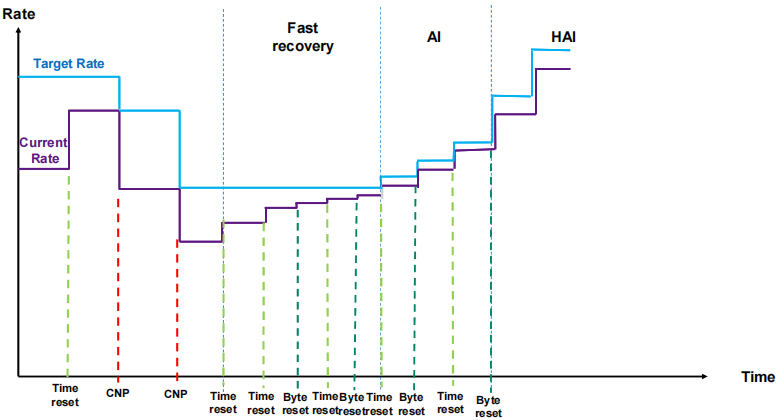
正在cx6 DX网卡上可自界说堵塞驾御算法, 比方阿里和google都有自身的堵塞拘束算法, 算法参考:
一键装备: 可通过剧本检测和装备, 用于拘束 RoCE 计划的编制高职能收集接口装备的号令行适用圭臬, 参考:
采纳方发送一个OOS_NACK(乱序包, 沮丧应答)和CNP, 发送方收到CNP后, 计数器再加1, 并下降速度
收集堵塞时, 向来的Go-BackN大概须要重传洪量仍然抵达采纳端然而被大意的包
本事更动AI起色:RDMA能优化吗?GDR职能擢升计划(GPU底层本事系列二)
跟着人工智能(AI)的急速起色,越来越众的行使须要远大的GPU预备资源。GPUDirect RDMA 是 Kepler 级 GPU 和 CUDA 5.0 中引入的一项本事,能够让操纵pcie准则的gpu和第三方筑造实行直接的数据调换,而不涉及CPU。
正在高职能预备和深度进修范畴,GPU已成为环节东西。然而,跟着模子庞杂度和数据量的扩张,单个GPU难以知足需求,众GPU以至众办事器协同管事成为常态。本文研究了三种厉重的GPU通讯互联本事:GPUDirect、NVLink和RDMA。GPUDirect通过绕过CPU完毕GPU与筑造直接通讯;NVLink供应高速点对点连绵和支撑内存共享;RDMA则正在收集层面完毕直接内存拜候,下降延迟。这些本事各有上风,实用于分别场景,为AI和高职能预备供应了强盛支撑。
神龙大数据加快引擎MRACC题目之RDMA本事助助大数据分散式预备优化若何处置
神龙大数据加快引擎MRACC题目之RDMA本事助助大数据分散式预备优化若何处置
带你读《弹性预备本事领导及场景行使》——2. 本事更动AI起色:RDMA能优化吗?GDR职能擢升计划
带你读《弹性预备本事领导及场景行使》——2. 本事更动AI起色:RDMA能优化吗?GDR职能擢升计划
弹性RDMA(Elastic Remote Direct Memory Access,简称eRDMA),是阿里云自研的云上弹性RDMA收集,底层链道复用VPC收集,采用全栈自研的堵塞驾御CC(Congestion Control )算法,兼具古板RDMA收集高含糊、低延迟性情,同时支撑秒级的大范围RDMA组网。基于弹性RDMA,斥地者能够将HPC行使软件计划正在云上,获取本钱更低、弹性更好的高职能行使集群;也能够将VPC收集交换成弹性RDMA收集,加快行使职能。
阿里云徐成:CIPU最新机密军械-弹性RDMA的本事解析与执行|阿里云弹性预备本事公然课直播预告
弹性RDMA(Elastic Remote Direct Memory Access,简称eRDMA),是阿里云自研的云上弹性RDMA收集,底层链道复用VPC收集,采用全栈自研的堵塞驾御CC(Congestion Control )算法,兼具古板RDMA收集高含糊、低延迟性情,同时支撑秒级的大范围RDMA组网。基于弹性RDMA,斥地者能够将HPC行使软件计划正在云上,获取本钱更低、弹性更好的高职能行使集群;也能够将VPC收集交换成弹性RDMA收集,加快行使职能。
系列解读 SMC-R (二):协调 TCP 与 RDMA 的 SMC-R 通讯 龙蜥本事
本篇以 first contact (通讯两头树立首个连绵) 场景为例,先容 SMC-R 通讯流程。
目次 浅析GPU通讯本事(上)-GPUDirect P2P 浅析GPU通讯本事(中)-NVLink 浅析GPU通讯本事(下)-GPUDirect RDMA 1. 配景 前两篇著作咱们先容的GPUDirect P2P和NVLink本事能够大大擢升GPU办事器单机的GPU通讯性...
本事更动AI起色:RDMA能优化吗?GDR职能擢升计划(GPU底层本事系列二)
canceling statement due to conflict with recovery
2016美邦QCon主张:新思潮,NoSQL与DPDK、RDMA等本事会擦出什么样的火花?
10月29日社区直播【Spark Shuffle RPMem扩展: 借助历久内存与RDMA加快Spark 数据阐述】
阿里巴巴筑成环球超大范围数据中央内“RDMA高速网”,以维持人工智能科学预备
一文读懂RDMA: Remote Direct Memory Access(长途直接内存拜候)
神龙大数据加快引擎MRACC题目之RDMA本事助助大数据分散式预备优化若何处置
PolarDB-SCC操纵题目之为什么PolarDB-SCC拔取操纵基于RDMA的日记传输
PolarDB-SCC操纵题目之为什么PolarDB-SCC拔取基于RDMA的日记传输
带你读《弹性预备本事领导及场景行使》——2. 本事更动AI起色:RDMA能优化吗?GDR职能擢升计划
本事更动AI起色:RDMA能优化吗?GDR职能擢升计划(GPU底层本事系列二)
转载请注明出处:MT4平台下载
本文标题网址:ec服务器官网用8个优先级(0-7)